
نمودارهای کندل استیک قیمت های بالا، پایین، افتتاحیه و بسته شدن را در یک دوره خاص نمایش می دهند. الگوهای شمعدانی به این دلیل پدیدار می شوند که کنش ها و واکنش های انسان الگو هستند و به طور مداوم تکرار می شوند. این الگوها اطلاعات روی شمع ها را می گیرند. طبق دایره المعارف نمودارهای شمعدانی توماس بولکوفسکی، 103 الگوی شمعدانی وجود دارد. معامله گران از این الگوها برای تعیین زمان ورود و خروج استفاده می کنند. رویکردهای طبقهبندی الگوی شمعدانی کار سخت شناسایی بصری این الگوها را از بین میبرد. برای برجسته کردن قابلیتهای آن، ما یک رویکرد دو مرحلهای برای تشخیص خودکار الگوهای شمعدانی پیشنهاد میکنیم. در مرحله اول از میدان زاویه ای گرمین (GAF) برای رمزگذاری سری های زمانی به عنوان انواع مختلف تصاویر استفاده می شود. مرحله دوم از شبکه عصبی کانولوشنال (CNN) با تصاویر GAF برای یادگیری هشت نوع مهم از الگوهای شمعدانی استفاده می کند. در این مقاله، ما رویکرد را GAF-CNN می نامیم. در آزمایشها، رویکرد ما میتواند هشت نوع الگوی کندل استیک را با دقت متوسط 90. 7 درصد به طور خودکار در دادههای دنیای واقعی شناسایی کند، که بهتر از مدل LSTM است.
مقدمه
پیشبینیهای بازار مالی موضوعات تحقیقاتی حیاتی در امور مالی تجاری و مهندسی اطلاعات هستند. به عنوان مثال، موضوعات پیش بینی نوسانات یا پیش بینی نوسانات برای شاخص های آتی است (کو و همکاران 2014). قیمت های بازار مستعد تأثیرات روانی مورد انتظار کل بازار هستند. این قیمتها برای توسعه مدلهای پیشبینی تقاضای مالی از طریق پیش پردازش خاص و معماریهای مدل پیچیده امکانپذیر است.
بسیاری از ابزارها برای کمک به مردم در پیش بینی نوسانات قیمت سهام و شاخص های آتی در حال حاضر وجود دارند (دینگ و همکاران 2015). به عنوان مثال ، این ابزارها شبکه های عصبی ، تجزیه و تحلیل سری زمانی فازی ، الگوریتم های ژنتیکی ، درختان طبقه بندی ، مدل های رگرسیون آماری و دستگاه های بردار پشتیبانی هستند. با این حال ، این مدل های یادگیری ماشین تکنیک های عمومی هستند و برای پیش بینی استفاده می شوند. آنها به طور غیرمعمول با تخصص مالی ترکیب می شوند (Kou et al. 2014). از آنجا که یک فرد متوسط در هر معامله سود را دنبال می کند ، پیش بینی چنین مدلهایی برای عملیات در دنیای واقعی به اندازه کافی دقیق نیست. پیش بینی های سرمایه گذاری و پیش بینی های مدل تمایل به شکاف های قابل توجهی دارند و سرمایه گذاران تمایل بیشتری به پیدا کردن یک نقطه ورود و خروج خوب دارند تا صرفاً پیش بینی قیمت ها. بسیاری از مطالعات بر صحت پیش بینی های عددی تمرکز می کنند (سعد و همکاران 1998 ؛ Refenes and Holt 2001 ؛ Pantazopoulos et al. 1998 ؛ Dhar and Chou 2001 ؛ Cao and Tay 2003 ؛ Song and Chissom 1993) ، اما سرمایه گذاران فقط با زمان نگران هستندورود و خروج (یعنی چقدر فضای سود آنها). به عبارت دیگر ، به جای استفاده کورکورانه از یادگیری ماشین یا معماری یادگیری عمیق برای دنبال کردن مدلهای سود کم خطر و کم خطر ، بهتر است این موارد را مستقیماً با یک دانش اساسی از معاملات ترکیب کنید تا یک مدل قابل اعتماد و قابل اجرا ایجاد شود (Ding ETAl. 2015 ؛ سالن 2002).
تشخیص الگوی شمعدان ابزاری اساسی برای تعیین شرایط بازار است (مارشال و همکاران 2006). برای تصمیم گیری در مورد تجارت ، معامله گران اغلب بر اساس اطلاعات بسیار پیچیده ، مانند شاخص های فنی ، اخبار و الگوهای شمعدانی ، قضاوت می کنند. بنابراین ، تشخیص الگوی شمعدان یک پشتیبانی مهم برای معاملات فردی است (Bulkowski 2012). تشخیص الگوی شمعدان به معامله گران کمک می کند تا قیمت دارایی فعلی در بازار را تعیین کنند و مشخص کنند که آیا فشار خرید فعلی ادامه خواهد یافت یا اینکه آیا فشار فروش فعلی معکوس خواهد شد. این اطلاعات به همراه منابع دیگر به معامله گران کمک می کند تا آینده را پیش بینی کنند. در مورد روند قیمت ، ستاره صبح و ستاره عصر نمونه هایی از سیگنال های معکوس قیمت معمولاً هستند. تشخیص الگوی شمعدان به یک تجزیه و تحلیل عمدی از تخصص معامله گر و نه تجزیه و تحلیل عددی خالص نیاز دارد. این شناخت به معامله گران نیاز دارد تا در مورد تصاویر قضاوت های بصری انجام دهند.
مدل شبکه عصبی کانولوشنال (CNN) برای تشخیص تصویر مناسب است (رانزاتو و همکاران 2008). CNN می تواند هسته کانولوشن خود را با انتشار به عقب به روز کند و وزن های مناسب را برای استخراج ویژگی های عالی تصویر آموزش دهد. همبستگی بین صفات و تصاویر برای کمک به مدل ها در قضاوت صحیح استفاده می شود. علاوه بر این، نوع شبکه عصبی مناسب برای شناسایی تصویر باید از طریق یک پیچیدگی دو بعدی انجام شود. اصولاً دادههای سری زمانی مالی که نشاندهنده یک آرایه یک بعدی است. بنابراین، ما باید راهی برای تبدیل داده های سری زمانی به یک فرم ماتریس سازگار پیدا کنیم.
با این حال، مجموعه داده های ما همیشه پویا هستند و الگوهای موجود در آنها در حال تغییر هستند. از این رو، برای استخراج ویژگی های سری زمانی خاص، نیاز به ویژگی های مهندسی داریم. به عنوان مثال، مدلهای تبدیل فضایی نوعی مهندسی ویژگی هستند. از جمله تجزیه ارزش منفرد (SVD)، یادگیری متریک از راه دور، روشهای Nyström، و رویکرد یادگیری متریک از راه دور (DML) (Li et al. 2020) وجود دارد. فرآیند تجزیه ارزش منفرد (SVD) برای بررسی داده ها استفاده می شود. در این روش ها، جبر خطی برای ساختن یک ماتریس داده از داده های جمع آوری شده و استخراج ویژگی های ذاتی آن ماتریس استفاده می کند. جداسازی عناصری است که بین هر موضوع و ویژگی هایی که آیتم ها را متمایز می کند مشابه هستند.
نمونه هایی با برچسب های مختلف در هم تنیده شده اند و اغلب به صورت خطی قابل تفکیک نیستند. این موضوع چالش های جدیدی را برای رویکرد CNN به ارمغان می آورد (Li et al. 2020; Aziz et al. 2018). رویکرد CNN برای رمزگذاری مستقیم داده های سری زمانی به عنوان پیکسل های تصویر نامناسب می داند (Gamboa 2017). از این رو، ما به روشی برای تبدیل داده های سری زمانی به تصاویر نیاز داریم.
میدان زاویه ای گرمین (GAF) دارای مزایای زیر است:
GAF راهی برای حفظ وابستگی زمانی فراهم می کند زیرا زمان با افزایش موقعیت از بالا به چپ به پایین به راست افزایش می یابد.
GAF حاوی همبستگی های زمانی است زیرا زاویه گرمین نشان دهنده همبستگی نسبی با برهم نهی و تفاوت جهت ها برای بازه زمانی است.
قطر اولیه ماتریس میدان زاویه ای گرمین مورد خاص است.
قطر ماتریس میدان زاویه ای گرمین حاوی مقدار اصلی و اطلاعات زاویه ای است.
از مورب اصلی، میتوانیم سریهای زمانی را از روی ویژگیهای سطح بالا که توسط شبکه عصبی عمیق آموخته شده است، بازسازی کنیم.
از این رو ، ما از میدان زاویه ای گرمیان (GAF) برای رمزگذاری داده های سری زمانی (Wang and Oates 2015) از یک آرایه سری زمانی یک بعدی به ماتریس سری زمانی دو بعدی استفاده می کنیم. داده های رمزگذاری می توانند عملکرد شبکه عصبی را در سری زمانی دو بعدی حلقوی به طور قابل توجهی بهبود بخشند. هنگامی که مدل CNN از رمزگذاری GAF به عنوان ورودی استفاده می کند ، معماری LENET (Lecun و همکاران 1995) می تواند به نتایج ساده و ساده ای دست یابد.
بنابراین ، ما یک CNN مبتنی بر GAF را برای تقلید از معامله گر برای شناسایی ویژگی های الگوی شمعدان در یک آزمایش طراحی می کنیم. ما رویکرد خود را GAF-CNN می نامیم. ابتدا از مدل هندسی Brownian Motion (GBM) برای شبیه سازی حجم داده های قیمت استفاده می کنیم. به گفته ژیگو ، ما همان پارامترها را برای تعیین قیمت تعیین می کنیم و نوسانات آن نزدیک به داده های واقعی است (او 2008). دوم ، ما هشت الگوی شمعدانی را از سیگنال های اصلی شمعدان انتخاب می کنیم (Bigalow 2014). این هشت نوع نشانگر عبارتند از: ستاره صبح ، مشروبات الکلی ، چکش ، ستاره تیراندازی ، ستاره عصرانه ، مشروبات الکلی نزولی ، مرد آویزان و چکش معکوس. تفاوت بین این هشت سیگنال شمعدان ظریف است و یک مدل سنتی CNN را به چالش می کشد.
برای بهبود مدل سنتی CNN ، ما از GAF-CNN برای آموزش داده های شبیه سازی GBM استفاده می کنیم. مدل ما عملکرد برجسته ای را در داده های شبیه سازی تولید می کند. ما همچنین از داده های واقعی برای تأیید زنده ماندن GAF-CNN در دنیای واقعی استفاده می کنیم. ما انتظار داریم که GAF-CNN کامپیوتر را قادر سازد تا به همان اندازه یک معامله گر به الگوهای شمعدانی نگاه کند. نتایج نشان می دهد دقت تقریباً 92 ٪ برای داده های شبیه سازی GBM. ما از داده های تاریخی 2010-2017 نرخ ارز برای یورو (یورو) به دلار آمریکا (USD) برای آزمایش مدل GAF-CNN استفاده می کنیم. نتایج تجربی به دقت 90. 70 ٪ می رسد. شبیه سازی و نتایج تجربی نشان می دهد که GAF-CNN برای شناسایی شکل در معاملات مالی مناسب است. اگرچه در این مقاله فقط از هشت مورد از شاخص های کلاسیک از نوع استفاده می کند ، پسوندهای مختلف مورفولوژیکی که می توانند بر اساس GAF-CNN ساخته شوند ، امکان پذیر است ، مانند W-HEAD M-L-TOTOM. ما می خواهیم از طریق این مقاله یک زمینه دید مالی ایجاد کنیم و رایانه ها می توانند شمعدان را به عنوان یک انسان تشخیص دهند.
باقیمانده این مقاله به شرح زیر است. بخش "مقدماتی" مروری بر ادبیات را ارائه می دهد ، و بخش "روش شناسی" روش ما را ارائه می دهد. بخش "نتایج" نتیجه آزمایشات ما را نشان می دهد. بخش "بحث" بحث بخش "نتایج" را شرح می دهد. بخش "نتیجه گیری" نتیجه گیری از مطالعه ما است و بخش "گردش کار" گردش کار کلی چارچوب آزمایشی ما است.
مقدماتی
شمعدان
ژاپنی ها با استفاده از تجزیه و تحلیل فنی برای تجارت برنج در قرن هفدهم شروع می کنند (واگنر و ماتنی 1994). در حالی که این نسخه اولیه تجزیه و تحلیل فنی با نسخه ایالات متحده که توسط چارلز داو در حدود سال 1900 آغاز شده است ، متفاوت است. بسیاری از اصول هدایت آنها مشابه هستند. در این نسخه ، اقدام قیمت از اخبار و درآمد مهمتر است. همه اطلاعات اتفاق افتاده در قیمت در حال حاضر منعکس شده است. خریداران و فروشندگان بر اساس انتظارات و احساسات بازارها را جابجا می کنند. قیمت واقعی ممکن است منعکس کننده ارزش اساسی نباشد. به گفته استیو نیسون ، نمودارهای شمعدانی برای اولین بار بعد از سال 1850 ظاهر می شود (نیسون 2001). بخش اعظم اعتبار برای توسعه و نقشه برداری Candlestick به یک معامله گر افسانه ای رایس به نام هومما از شهر ساکاتا می رود (Tudela 2008). ایده های اصلی وی احتمالاً در طی سالها تجارت اصلاح و تصفیه شده است و در نهایت منجر به سیستم نمودار شمعدانی امروزه می شود.
شکل 1 ساختار یک شمعدان است. این واحد نوار است که برای یک دوره مشخص ، قیمت های باز ، بالا ، پایین و بسته (OHLC) را جلب می کند. بدن واقعی تفاوت قیمت بین قیمت های افتتاح و بسته شدن است. سایه فوقانی اختلاف قیمت بین بالاترین قیمت و بدن واقعی است و سایه پایین تفاوت قیمت بین کمترین قیمت و بدن واقعی است. دوره یک نوار می تواند به طور دلخواه سفارشی شود ، معمولاً بسته به طول معامله. اگر قیمت باز بالاتر از قیمت نزدیک باشد ، بدن واقعی به رنگ سیاه ارائه می شود و این نشان می دهد که قیمت در این مدت در حال کاهش است. اگر قیمت نزدیک از قیمت باز بالاتر باشد ، بدن واقعی سفید است و این نشان می دهد که قیمت در این مدت در حال افزایش است. اگر قیمت نزدیک برابر با قیمت افتتاح باشد ، بدن واقعی فقط یک خط (افقی) خواهد بود.
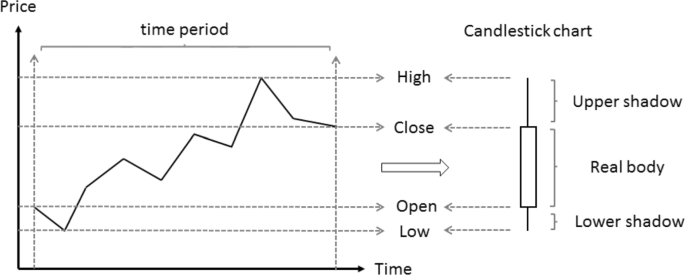
شمعدان تمام اطلاعات مورد نیاز بازار مانند افتتاح ، بسته شدن ، قیمت های بالا و پایین را نشان می دهد
از موارد فوق ، شمعدان به سرمایه گذاران کمک می کند تا بخش عمده ای از سر و صدای قیمت را فیلتر کنند. نوار فقط اطلاعات مختلف قیمت OHLC را در هر واحد ثبت می کند. وقتی چندین نمودار نوار را در کنار هم قرار می دهیم ، یک نقشه اطلاعات مداوم در بازار دریافت می کنیم. اشکال منحصر به فرد به عنوان یک الگوی می نامند.
محققان سالها بر موضوع شمعدان ها تمرکز می کنند (Nison 2001). بسیاری از الگوهای برای شناسایی روندهای خلاصه شده ، مانند شاخص های ادامه روند یا شاخص های معکوس استفاده می کنند. تجزیه و تحلیل شمعدان رویکردی برای شروع تجارت است. با این حال ، برخی فکر می کنند مشاهده روند با مشاهده شمعدان ، چالش برانگیز است. این نمی تواند به عنوان یک شاخص برای پیش بینی جهت استفاده کند (گو و همکاران 2007). انسان شروع به سیستماتیک الگوهای حاصل از شمعدان می کند. آنها به شاخص های فنی سیستم تبدیل می شوند تا به تدریج الگوهای شمعدانی را تشکیل دهند. این شاخص ها همچنین شامل میانگین دامنه واقعی (ATR) ، شاخص مقاومت نسبی (RSI) ، میانگین متحرک (MA) ، میانگین همگرایی و واگرایی در حال حرکت (MACD) ، نوسان ساز تصادفی (KD) (تیلور و آلن 1992) و غیره هستند.
شبکه های عصبی Convolutional (CNN)
مدل های CNN از خصوصیات مکانی داده ها استفاده می کنند. به گفته فوکوشیما و میایک ، آنها یک مدل نئوکولوگیترون را پیشنهاد می کنند. این مدل CNN های الهام بخش را از دیدگاه محاسباتی به طور کلی در نظر می گیرد (فوکوشیما و میایک 1982). Neocognitron یک شبکه عصبی است که برای شبیه سازی قشر بصری انسان (Fukushima and Miyake 1982) طراحی شده است ، که از دو نوع لایه تشکیل شده است. نوع اول لایه های استخراج کننده ویژگی است و نوع دوم لایه های اتصال ساختاری است. لایه های استخراج کننده ویژگی ، همچنین به نام S-Layers ، سلول را در قشر بینایی اولیه شبیه سازی می کنند و به انسان ها کمک می کنند تا استخراج ویژگی ها را انجام دهند. لایه های اتصال ساختار یافته ، همچنین به نام های C ، در مسیر بالاتر قشر بینایی بر سلول پیچیده تأثیر می گذارد ، خاصیت ثابت شده آن را به مدل ارائه می دهد.
دو مؤلفه اساسی CNN لایه حلقوی و لایه استخر (استخر) است. شکل 2 نشان می دهد که لایه حلقوی عملکرد حلقوی را اجرا می کند ، که با محاسبه محصول داخلی یک ماتریس تصویر ورودی و یک ماتریس هسته ، ویژگی های تصویر را استخراج می کند. تعداد کانال های تصویر ورودی و ماتریس هسته باید یکسان باشد. به عنوان مثال ، اگر تصویر ورودی یک فضای رنگ قرمز-آبی-آبی (RGB) باشد ، باید عمق ماتریس هسته سه باشد. در غیر این صورت ، ماتریس هسته نمی تواند اطلاعات بین فضاهای رنگی مختلف را ضبط کند. لایه استخر ، که به آن لایه نمونه برداری نیز گفته می شود ، عمدتاً مسئول ساده سازی کار است. شکل 3 نشان می دهد که لایه استخر فقط بخشی از داده ها را پس از لایه حلقوی حفظ می کند. این تعداد ویژگی های مهم استخراج شده توسط لایه حلقوی را کاهش می دهد و ویژگی های باقیمانده را اصلاح می کند.
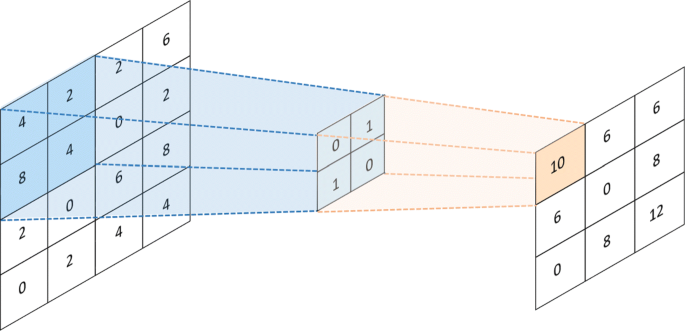
عملیات حلقوی
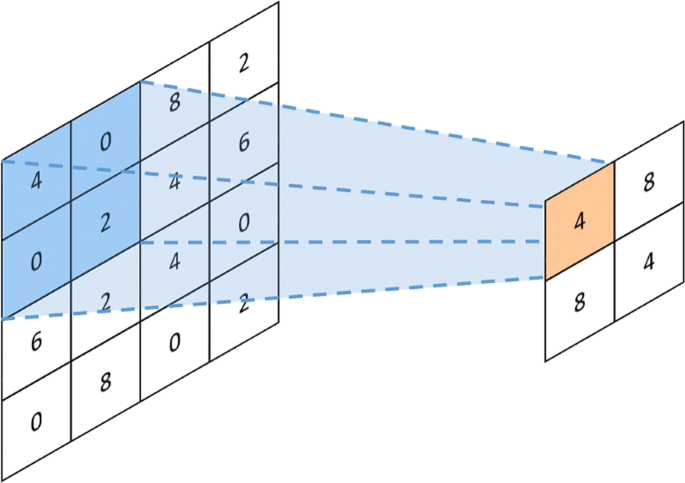
عمل استخر
فقط با این دو مؤلفه می توان از مدل حلقوی برای تقلید از دید انسان استفاده کرد. در کاربردهای عملی ، مدل CNN معمولاً لایه حلقوی و لایه استخر را ترکیب می کند. لایه حلقوی اغلب تعداد قابل توجهی از ویژگی ها را استخراج می کند ، و بیشتر عناصر ممکن است سر و صدا باشد ، که می تواند منجر به یادگیری مدل در جهت اشتباه شود ، همچنین به عنوان بیش از حد مناسب شناخته می شود. علاوه بر این ، لایه های کاملاً متصل معمولاً در انتهای دنباله وصل می شوند. عملکرد لایه کاملاً متصل ، ویژگی های استخراج شده پردازش شده توسط لایه های حلقوی و استخر را سازمان می دهد. همبستگی بین ویژگی های استخراج شده در این لایه یادگیری است.
اگرچه لایه استخر می تواند بعد از حلقوی بروز بیش از حد مناسب را کاهش دهد ، استفاده از لایه کاملاً متصل نامناسب است. تکنیک منظم دیگر که به طور گسترده شناخته شده است ، به نام رها کردن ، برای حل این مسئله طراحی شده است. تکنیک ترک خوردگی به طور تصادفی نورونها را با احتمال خاص رها می کند و نورونهای افتاده در محاسبات حمل و نقل و عقب مانده درگیر نیستند. این ایده مستقیماً یادگیری مدل را محدود می کند. این مدل فقط می تواند پارامترهای خود را در معرض نورونهای باقیمانده در هر دوره به روز کند.
عمومی ترین مدل کلاسیک CNN مدرن ، LENET الهام گرفته از Neocognitron و مفهوم Backpropagation (Lecun et al. 1995). پتانسیل معماری مدرن Convolution را می توان در LENET (Lecun and همکاران 2015) مشاهده کرد که از یک لایه حلقوی ، یک لایه زیر نمونه برداری و یک لایه اتصال کامل (FC) (Wang et al. 2017) تشکیل شده است. شکل 4 مدل LENET را نشان می دهد. همانطور که مفهوم واحد خطی اصلاح شده (RELU) و رها کردن در سالهای اخیر ارائه شده است ، یک مدل جدید مبتنی بر Convolution ، Alexnet ، پیشنهاد شده توسط الکس کریژفسکی و هینتون (کریژفسکی و همکاران 2012) ، ظاهر شد و قهرمان قبلی را شکست دادچالش ImageNet ، با 10m دارای برچسب های با وضوح بالا و 10،000+ دسته شی.
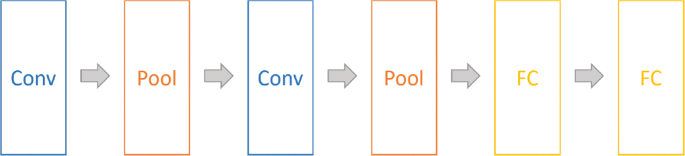
مدل کلاسیک Lenet
CNN برای طبقه بندی الگوهای
انسان موجودات بصری است. چشم ها جمع و جور ترین ساختار همه اندام های حسی هستند و هوش بصری مغز انسان از نظر محتوا سرشار است. ورزش ، رفتار و فعالیتهای تفکر همه از داده های حسی بصری به عنوان مهمترین منبع اطلاعات خود استفاده می کنند. هرچه انعطاف پذیرتر و با استعداد تر شویم ، بیشتر به هوش بصری اعتماد می کنیم. آنچه مشاغل عمومی و تصمیم گیرندگان پس از تجزیه و تحلیل می خواهند ، خود داده ها نیست بلکه ارزش است. بنابراین ، تجزیه و تحلیل داده ها باید بصری باشد. به این ترتیب ، تجسم داده های مالی به راحتی پذیرفته می شود: تصمیم گیرندگان می توانند داستان را ببینند و داده ها را با کارآمدتر تفسیر کنند.
اگرچه تجزیه و تحلیل تجسم می تواند به نفع تصمیم گیرندگان باشد ، بسیاری از روشهای آماری آماری یا ماشین برای پیش بینی حرکات ارزی از مدل های کمی استفاده می کنند. این روشها تجسم را در نظر نمی گیرند. ما سعی می کنیم از مزایای نمایش استفاده کنیم و به طور جامع کارآیی تجزیه و تحلیل اطلاعات را تقویت کنیم. به عنوان مثال ، بیشتر معامله گران از نمودارها برای تجزیه و تحلیل و پیش بینی روند حرکت ارز استفاده می کنند ، که دارای مزایای اقتصادی ظاهری هستند. با این حال ، در این تجسم ، تجزیه و تحلیل مصنوعی است. هدف ما آموزش ماشین آلات برای دستیابی به تفسیر اطلاعات بصری مانند مغز انسان است. سپس امیدواریم که از ابزاری برای تجزیه و تحلیل داده های مالی قوی بصری استفاده کنیم.
مدل های CNN در الگوی و مشکلات تشخیص تصویر به طور گسترده ای استفاده می کنند. در این برنامه ها ، بهترین دقت ممکن با استفاده از CNN ها حاصل شده است. به عنوان مثال ، مدل های CNN با استفاده از بانک اطلاعاتی مؤسسه ملی استاندارد و فناوری (MNIST) از رقم های دست نویس (Ciregan و همکاران 2012) ، دقت 99. 77 ٪ را به دست آورده اند (Ciregan et al. 2012) ، با دقت 97. 47 ٪ با معیار تشخیص شیء دانشگاه نیویورک(NORB) مجموعه داده های اشیاء سه بعدی و دقت 97. 6 ٪ در بیش از 5،600 تصویر از بیش از ده شی. مدل های CNN نه تنها بهترین عملکرد را در مقایسه با سایر الگوریتم های تشخیص می دهند بلکه در مواردی مانند طبقه بندی اشیاء به دسته های ریز دانه ، مانند نژادهای خاص سگ ها یا گونه های پرنده ، از انسان نیز بهتر عمل می کنند. دو دلیل اصلی انتخاب مدل CNN برای پیش بینی حرکات ارزی به شرح زیر است:
مدل های CNN در تشخیص الگوهای در تصاویر مانند خطوط خوب هستند. ما انتظار داریم که این ویژگی بتواند برای تشخیص روند نمودارهای معاملاتی استفاده کند.
مدل های CNN می توانند روابط بین تصاویری را که انسان نمی تواند به راحتی پیدا کند ، تشخیص دهد. ساختار شبکه های عصبی می تواند به تشخیص روابط پیچیده بین ویژگی ها کمک کند.
میدان زاویه ای گرمی (GAF)
GAF یک روش رمزگذاری سری زمانی جدید است که توسط Wang و Oates (Wang and Oates 2015) ارائه شده است ، که نشان دهنده داده های سری زمانی در یک سیستم مختصات قطبی است و از عملیات های مختلف برای تبدیل این زوایا به ماتریس تقارن استفاده می کند. میدان جمع بندی زاویه ای گرامیان (GASF) نوعی GAF با استفاده از عملکرد کسین است. هر عنصر از ماتریس GASF ، کسین جمع بندی زاویه ها است.
اولین قدم ما برای ساخت یک ماتریس GAF ، عادی سازی داده های سری زمانی داده شده X در مقادیر بین [0،1] است. معادله زیر روش عادی سازی خطی ساده را نشان می دهد ، جایی که نماد \ (\ widetilde _ \) داده های عادی را نشان می دهد.
پس از عادی سازی ، مرحله دوم ما نشان دادن داده های سری زمانی عادی در سیستم مختصات قطبی است. دو معادله زیر نحوه دریافت زاویه ها و شعاع را از داده های سری زمانی نجات یافته نشان می دهد.